Execução de Software
Tecnologias Utilizadas
Para o desenvolvimento do Ovnitrap, utilizamos as seguintes tecnologias, conforme o projeto, a saber:
- Frontend: React Native via Expo, Typescript e CSS
- Backend: Django Rest Framework e Python
- Visão Computacional: YOLOv5 e Python
- DevOps: Docker, Docker Compose, Gitlab e Gitlab Pages
Organização das Atividades
A equipe foi dividida em áreas de especialização para maximizar a eficiência e a qualidade do trabalho:
-
Frontend: Desenvolvimento de interfaces e experiência do usuário no aplicativo;
- Envolvidos: Victor, Luan, Luís Lins e Luiz Guilherme
-
Backend: Implementação da API, lógica do servidor e modelagem do banco de dados ORM;
- Envolvidos: Lucas, Kayro e Luís Lins
-
Visão Computacional: Treinamento e implementação de modelo de detecção de larva;
- Envolvidos: Kayro e Lucas Gabriel
-
DevOps: Definição dos ambientes de execução, revisão de código e supervisão geral.
- Envolvidos: Luís Lins
Para cada Stack (e também para a documentação), foi criado um repositório a fim de separar as bases de código independentes, facilitar a política de branches e facilitar a atribuição de responsabilidade de cada tarefa. Os repositórios são:
O líder de qualidade criou, em diálogo com todo o grupo, as Sprints a serem cumpridas até a data de entrega do projeto. Elas foram montadas tendo em vista o que deve ser entregue em cada ponto de controle e os requisitos funcionais e não-funcionais do projeto. As sprints tem duração de uma semana e utiliza a funcionalidade de Milestones do Gitlab.
Em cada repositório, os líderes de cada área criaram Issues das tarefas a serem desenvolvidas naquela Sprint e delegaram aos respectivos desenvolvedores, os quais foram acompanhados ao longo da semana. Essa comunicação visa principalmente identificar empecilhos e dificuldades no desenvolvimento, em especial no Frontend, visto que usa uma tecnologia pouco familiar para a equipe.
Cada um dos repositórios tem uma política de branches, para facilitar o desenvolvimento paralelo e diminuir a quantidade de conflitos. Dessa forma, a branch develop é a branch principal de desenvolvimento e a cada Issue o integrante criava uma branch separada para elaborar sua atividade. Ao fim dela, o desenvolvedor criava um Merge Request para a branch develop, que era revisado e avaliado pelo líder de qualidade. Além disso, destaca-se que durante o período das aulas de PI2, o grupo se reunia em força-tarefa para desenvolver o máximo possível em grupo, a fim de validar dúvidas rapidamente.
Implementação do Frontend
O código desenvolvido na aplicação React Native é dividido em 5 principais tipos, a saber: páginas, subcomponentes, serviços, constantes e assets.
- Subcomponentes: É um elemento reutilizável de função única no projeto. Por exemplo: botões e caixas de informação.
- Serviços: Funções para comunicação com a API e gerenciamento de armazenamento.
- Constantes: Valores fixos utilizados na aplicação, podendo ser de estilização ou de lógica.
- Constantes: Imagens e estilos usados no aplicativo.
- Páginas: É o componente de tela completo, composto por diversos subcomponentes, chamadas à serviços, estilizado por assets e utilizando constantes.
Resultados
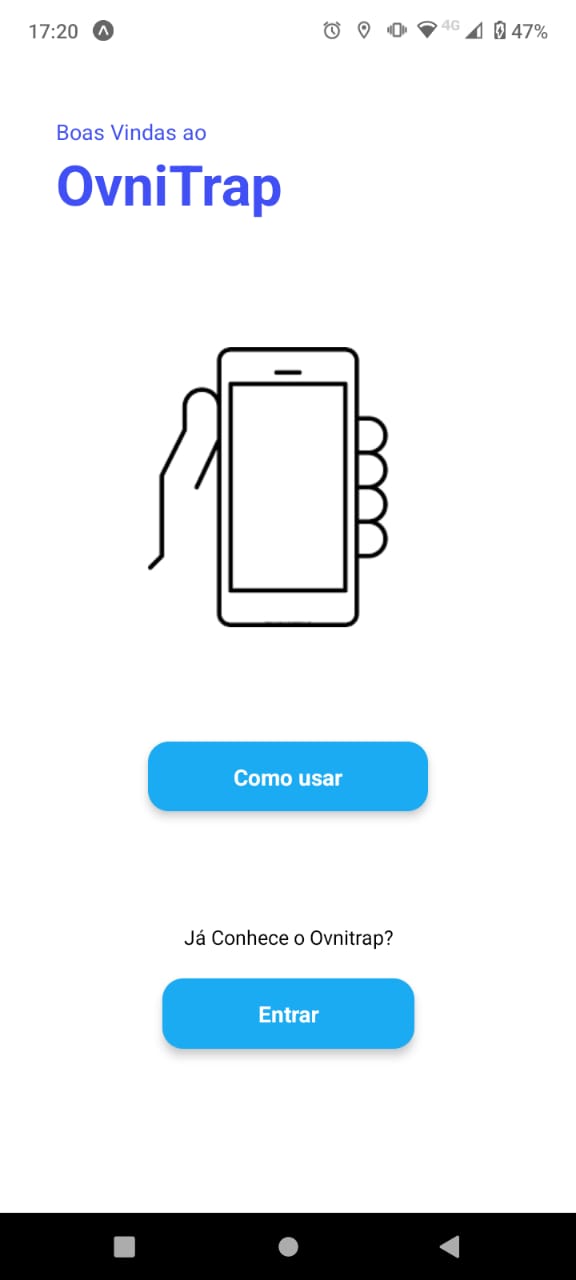
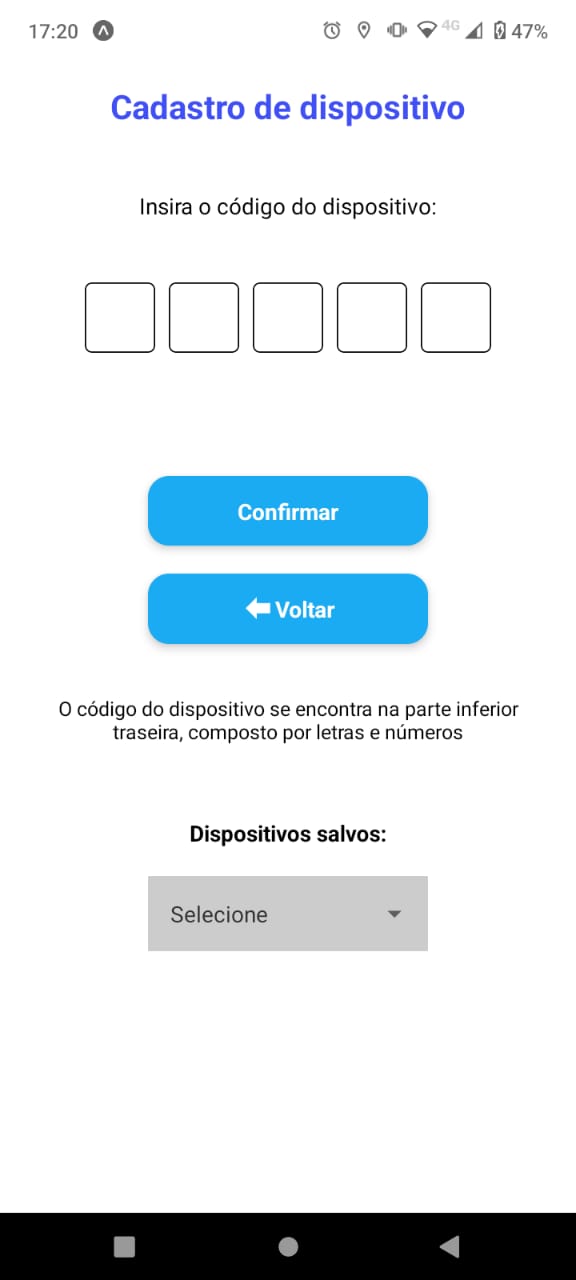
Durante o desenvolvimento do aplicativo, a equipe enfrentou dificuldades no que diz respeito à estilização de certa forma limitada de uma aplicação React Native, mas não teve problemas técnicos que impedicem o andamento da equipe. Será implementado para o ponto de controle 3 um menu inferior a partir da tela de dashboard, a fim de auxiliar o usuário à navegar pelas telas, em especial, usuários de IOS que não possuem o botão de voltar do Android. Portanto, o aplicativo foi desenvolvido com certa rapidez e o tempo restante foi populado por discussões acerca do armazenamento de dados e da integração com o Backend. Além disso, foi feito um protótipo de alta fidelidade que pode ser acessado abaixo:
No estado atual do aplicativo, o usuário consegue:
- Cadastrar novas armadilhas no app;
- Selecionar alguma armadilha que já tenha cadastrado;
- Visualizar um tela de explicação de como que se usa o aplicativo;
- Visualizar os indicadores na tela principal da armadilha
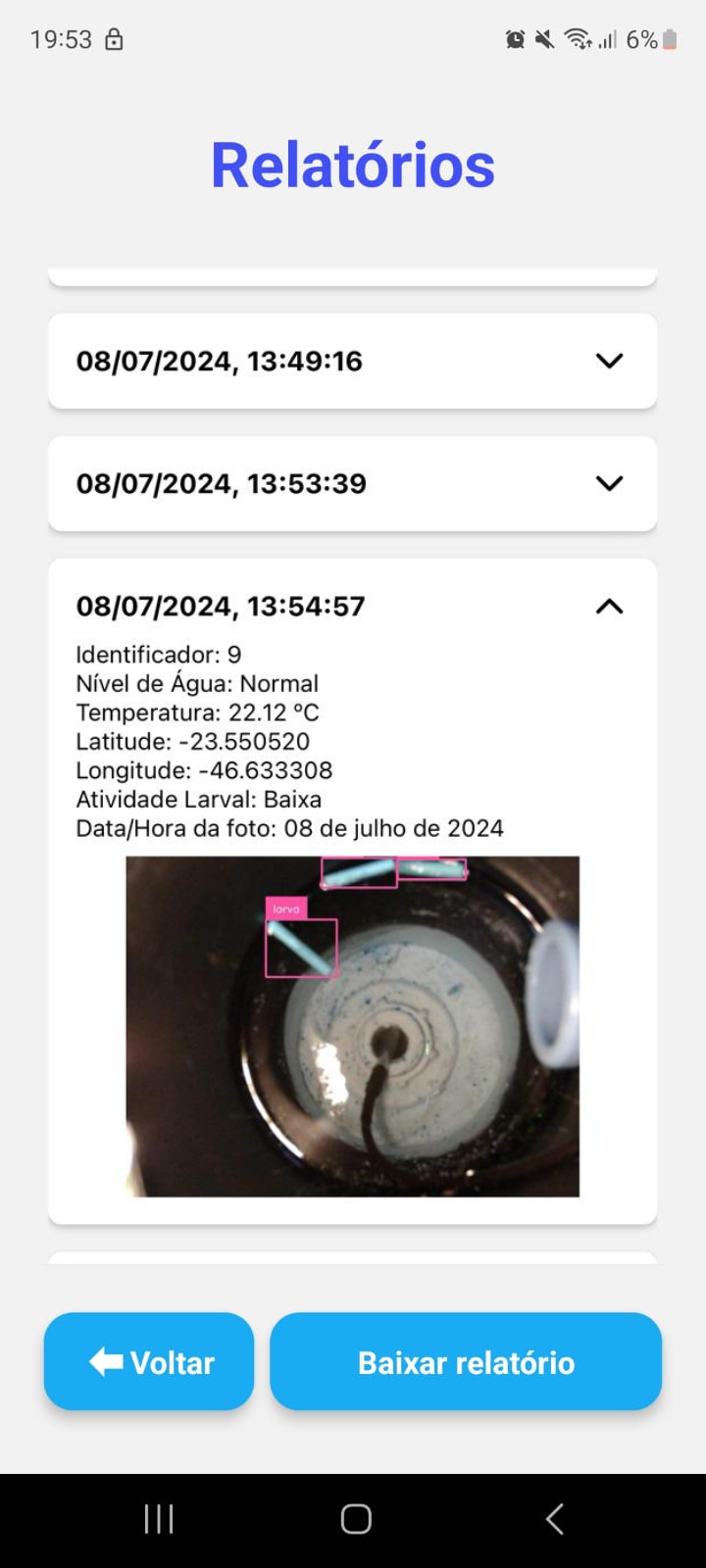
- Visualizar o relatório completo, por data/hora, da armadilha selecionada;

Implementação do Backend
O Backend serve apenas como uma API para integrar o Frontend com o banco de dados, dessa forma, a escolha do Django Rest Framework foi interessante visto que acelerou muito o desenvolvimento e a modelagem do banco de dados ORM. Além disso, não foi necessário se preocupar muito com segurança visto que o próprio Framework já possui funções internas que tratam dos principais erros e perigos de uma API. As requisições aceitas até então são de criação (POST) e de recuperação (GET) visto que não temos nem exclusão e nem edição de dados.
A organização das pastas e arquivos no backend foi estruturada para facilitar a manutenção e a escalabilidade, seguindo o próprio padrão do Django, criando um app por tabela no banco de dados:
- apps: Armadilha e Relatório
- models: Cada app tem um arquivo model que explicita o conteúdo/atributos da tabela no banco de dados
- serializers: Cada app tem um arquivo serializer que representa a classe que prepara os dados da model para apresentá-los nos endpoints
- views: Cada app tem um arquivo view com funções que recebem e tratam as requisições HTTP, retornando de forma respectiva.
- urls: O app principal da aplicação contem um arquivo urls, que contém os endereços acessíveis por quem consumir a API.
Os principais endpoints incluem:
-
GET /armadilhas: Retorna o identificador e aplelido de todas as armadilhas -
GET /armadilhas/<id>: Verifica a existência de uma armadilha com esse identificador e a retorna -
GET /armadilhas/<id>/relatorios: Retorna todos os relatórios da armadilha com esse identificador -
GET /relatorios: Retorna todos os relatórios -
GET /relatorios/recentes: Retorna o relatório mais recentes de cada armadilha
Resultados
Diante do exposto, a API foi desenvolvida sem muito esforço e atende completamente as demandas até agora mapeadas no aplicativo, isso é, o usuário consegue cadastrar uma armadilha e visualizar os seus relatórios, inclusive a imagem associada a cada relatório.
Implementação da Visão Computacional
Por que o YOLO?
Pesquisamos alguns algoritmos de aprendizado de máquina como ViT-Base, CvT-13, ConvNeXT, ResNet-18 e algumas diferentes versões do yolo. Baseado nos artigos, observamos que o yolo tem uma maior precisão para o contexto de detecção de larvas de mosquito da dengue, dado o tamanho reduzido das mesmas em condições normais.
YOLOv5, ou “You Only Look Once”, é um algoritmo de detecção de objetos baseado em deep learning que se destaca por sua rapidez e eficiência. Ele foi desenvolvido para detectar múltiplos objetos em uma imagem. Essa abordagem se diferencia de outros algoritmos que dividem a tarefa em duas etapas: identificar regiões de interesse e classificar os objetos nessas regiões.
Com o YOLOv5 no TensorFlow, há um modelo de rede neural é capaz de reconhecer objetos em diversas categorias, incluindo pessoas, carros, animais e muitos outros. No contexto atual, em que a análise de imagens e vídeos desempenha um papel fundamental em diversas áreas, desde segurança até automação industrial, ter um sistema eficiente de detecção de objetos é essencial
Como foi feito?
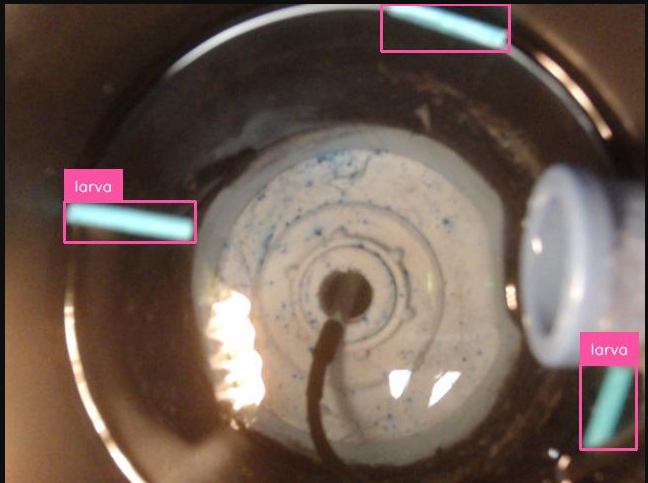
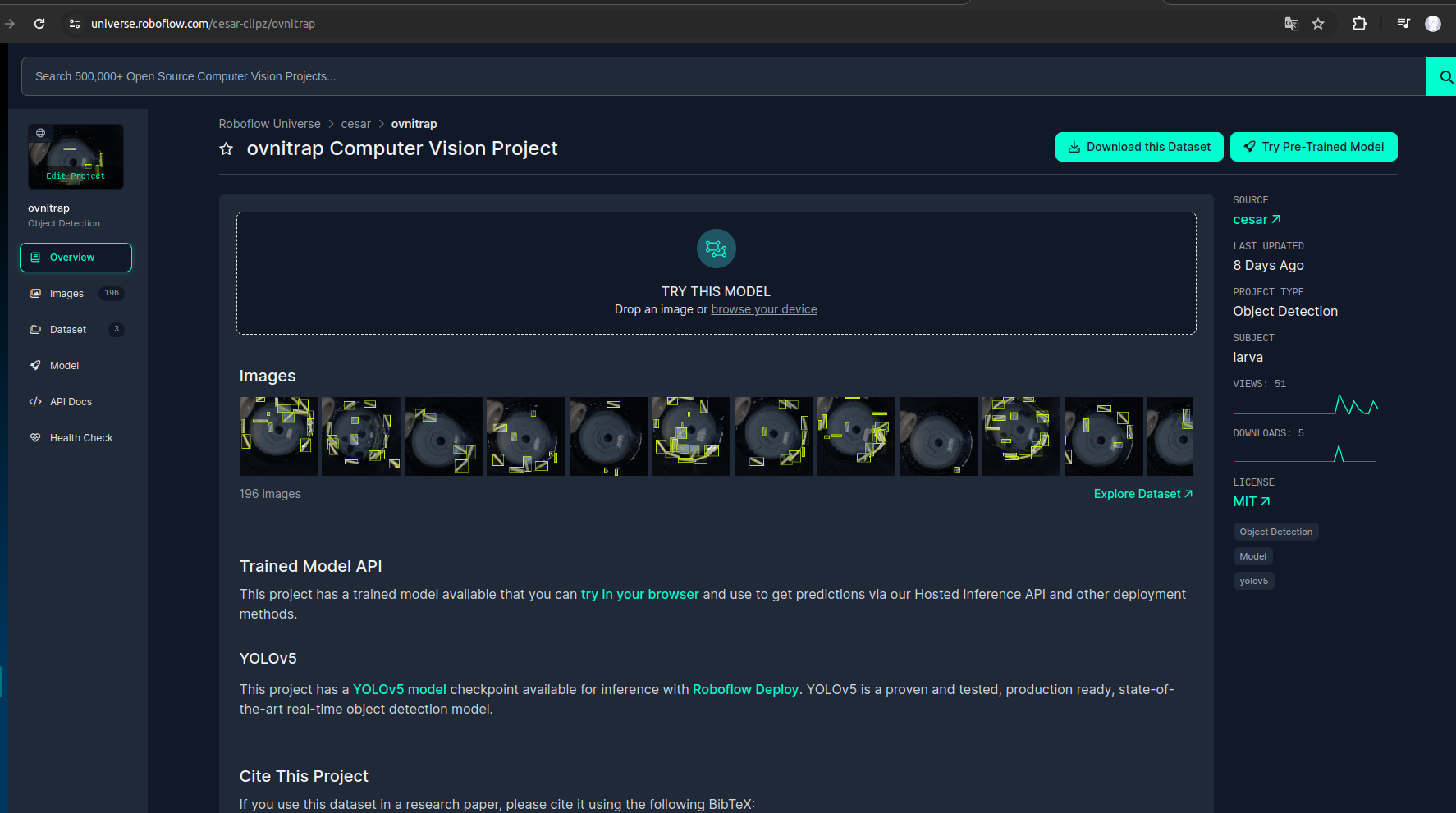
Inicialmente, foi necessário aguardar o ambiente da armadilha ficar pronto com todas as suas estruturas devidamente montadas, de forma que o mesmo ficasse o mais fiel possível ao cenário de uso. Em seguida, utilizamos pequenos tubos plásticos para simular o que seria a presença de larvas no ambiente da armadilha. Os tubos foram colocados na água em diversas posições e quantidades, para a captura de fotos variadas e em diferentes contextos para melhorar a precisão do modelo.
Além disso, em algumas fotos foram acrescentados elementos que serviam como ruído , de maneira que tal ruido não fosse detectado como um objeto a ser identificado. Abaixo são apresentadas algumas imagens capturadas durante esse processo, conseguimos produzir cerca de 200 fotos para o dataset, ressalta-se que a limitação da quantidade se deu em vista do pouco tempo disponível com o ambiente pronto, da dificuldade para reproduzir os diferentes cenários das fotos,tendo em vista a necessidade de movimentar a água em cada foto, e também da ausência de interface gráfica na captura das fotos, uma vez que foram capturadas utilizando o terminal da Raspberry Pi que tinha uma webcam conectada na mesma.






- Obs: Todas as fotos capturadas podem ser acessadas no repositório de visão computacional, na pasta dataset.
Como foi treinado?
O modelo foi treinado utilizando um dataset composto pelos fotos tiradas no ambiente da armadilha e citadas no tópico anterior. Para isso foi necessário anotar cada uma das imagens do dataset de forma manual. A anotação de cada imagem é um processo que envolve demarcar com um retângulo a posição exata do(s) objeto(s) que se deseja identificar, para isso utilizamos a ferramenta de rotulação presente no Roboflow.

Uma vez anotadas todas as imagens e tendo em vista o tamanho reduzido do dataset, foram aplicadas técnicas de aumento de dados para melhorar o treinamento do modelo, gerando três variações de cada imagem, uma versão dela com inversão horizontal, uma versão com rotação em 90 graus no sentido horário e outra anti-horário, e outra versão com ajustes de saturação entre -25% e +25%. Essas aumentações visaram o aumento da quantidade de fotos para treinamento do modelo e a variabilidade de cenários. Dessa forma, o dataset passou a ter (em termos de treinamento), cerca de 470 imagens, considerando as variações de cada imagem.
Ao final, é possivel exportar as imagens anotadas para diversos formatos específicos, em nosso contexto utilizamos o formato 'YOLO v5 PyTorch', em que o dataset é divido em imagens e suas labels associadas no formato suportado pelo Yolo.
Com as imagens e suas labels associadas, é possível treinar um modelo de detecção de objetos no YOLOv5. Ao final do treinamento, é gerado um arquivo de pesos personalizados da rede neural chamado 'best.pt'. Esse arquivo permite realizar a detecção utilizando o conhecimento adquirido pela rede neural durante o treinamento com o dataset personalizado.
Uma vez treinado o modelo, o mesmo pode ser utilizado de forma offline em diversos dispositivos, desde que atendam os requisitos mínimos exigidos pelo YoloV5, tenham as dependências e arquivos necessários, além do arquivo de peso obtido a partir do treinamento.
Deploy
Inicialmente o modelo rodava localmente na raspberry pi, mas por questões de performance foi necessário realizar o deploy do mesmo para utilizá-lo como serviço durante a execução do fluxo na mesma.
- Link do deploy: https://universe.roboflow.com/cesar-clipz/ovnitrap.
Resultado de imagem capturada no ambiente